Merge Data & Dissolve Polygons#
By: Steven Chao
Learning Objectives
Import dataframes into Python for analysis
Perform basic dataframe column operations
Merge dataframes using a unique key
Group attributes based on a similar attribute
Dissolve vector geometries based on attribute values
Review
Introduction#
Dataframes are widely used in Python for manipulating data. Recall that a dataframe is essentially an Excel spreadsheet (a 2-D table of rows and columns); in fact, many of the functions that you might use in Excel can often be replicated when working with dataframes in Python!
This chapter will introduce you to some of the basic operations that you can perform on dataframes. We will use these basic operations in order to calculate and map poverty rates in the Commonwealth of Virginia. We will pull data from the US Census Bureau’s American Community Survey (ACS) 2019 (see this page for the data).
# Import modules
import matplotlib.pyplot as plt
import pandas as pd
import geopandas as gpd
from census import Census
from us import states
import os
Accessing Data#
Import census data#
Let’s begin by accessing and importing census data. Importing census data into Python requires a Census API key. A key can be obtained from Census API Key. It will provide you with a unique 40 digit text string. Please keep track of this number. Store it in a safe place.
# Set API key
c = Census("CENSUS API KEY HERE")
With the Census API key set, we will access the census data at the tract level for the Commonwealth of Virginia from the 2019 ACS, specifically the ratio of income to poverty in the past 12 months (C17002_001E, total; C17002_002E, < 0.50; and C17002_003E, 0.50 - 0.99) variables and the total population (B01003_001E) variable. For more information on why these variables are used, refer to the US Census Bureau’s article on how the Census Bureau measures poverty and the list of variables found in ACS.
The census package provides us with some easy convenience methods that allow us to obtain data for a wide variety of geographies. The FIPS code for Virginia is 51, but if needed, we can also use the us library to help us figure out the relevant FIPS code.
# Obtain Census variables from the 2019 ACS at the tract level for the Commonwealth of Virginia (FIPS code: 51)
# C17002_001E: count of ratio of income to poverty in the past 12 months (total)
# C17002_002E: count of ratio of income to poverty in the past 12 months (< 0.50)
# C17002_003E: count of ratio of income to poverty in the past 12 months (0.50 - 0.99)
# B01003_001E: total population
# Sources: https://api.census.gov/data/2019/acs/acs5/variables.html; https://pypi.org/project/census/
va_census = c.acs5.state_county_tract(fields = ('NAME', 'C17002_001E', 'C17002_002E', 'C17002_003E', 'B01003_001E'),
state_fips = states.VA.fips,
county_fips = "*",
tract = "*",
year = 2017)
Now that we have accessed the data and assigned it to a variable, we can read the data into a dataframe using the pandas library.
# Create a dataframe from the census data
va_df = pd.DataFrame(va_census)
# Show the dataframe
print(va_df.head(2))
print('Shape: ', va_df.shape)
NAME C17002_001E C17002_002E \
0 Census Tract 60, Norfolk city, Virginia 3947.0 284.0
1 Census Tract 65.02, Norfolk city, Virginia 3287.0 383.0
C17002_003E B01003_001E state county tract
0 507.0 3947.0 51 710 006000
1 480.0 3302.0 51 710 006502
Shape: (1907, 8)
By showing the dataframe, we can see that there are 1907 rows (therefore 1907 census tracts) and 8 columns.
Import Shapefile#
Let’s also read into Python a shapefile of the Virginia census tracts and reproject it to the UTM Zone 17N projection. (This shapefile can be downloaded on the Census Bureau’s website on the Cartographic Boundary Files page or the TIGER/Line Shapefiles page.)
# Access shapefile of Virginia census tracts
va_tract = gpd.read_file("https://www2.census.gov/geo/tiger/TIGER2019/TRACT/tl_2019_51_tract.zip")
# Reproject shapefile to UTM Zone 17N
# https://spatialreference.org/ref/epsg/wgs-84-utm-zone-17n/
va_tract = va_tract.to_crs(epsg = 32617)
# Print GeoDataFrame of shapefile
print(va_tract.head(2))
print('Shape: ', va_tract.shape)
# Check shapefile projection
print("\nThe shapefile projection is: {}".format(va_tract.crs))
STATEFP COUNTYFP TRACTCE GEOID NAME NAMELSAD MTFCC \
0 51 700 032132 51700032132 321.32 Census Tract 321.32 G5020
1 51 700 032226 51700032226 322.26 Census Tract 322.26 G5020
FUNCSTAT ALAND AWATER INTPTLAT INTPTLON \
0 S 2552457 0 +37.1475176 -076.5212499
1 S 3478916 165945 +37.1625163 -076.5527816
geometry
0 POLYGON ((897174.191 4119897.084, 897174.811 4...
1 POLYGON ((893470.562 4123469.385, 893542.722 4...
Shape: (1907, 13)
The shapefile projection is: EPSG:32617
By printing the shapefile, we can see that the shapefile also has 1907 rows (1907 tracts). This number matches with the number of census records that we have on file. Perfect!
Not so fast, though. We have a potential problem: We have the census data, and we have the shapefile of census tracts that correspond with that data, but they are stored in two separate variables (va_df and va_tract respectively)! That makes it a bit difficult to map since these two separate datasets aren’t connected to each other.
Performing Dataframe Operations#
Create new column from old columns to get combined FIPS code#
To solve this problem, we can join the two dataframes together via a field or column that is common to both dataframes, which is referred to as a key.
Looking at the two datasets above, it appears that the GEOID column from va_tract and the state, county, and tract columns combined from va_df could serve as the unique key for joining these two dataframes together. In their current forms, this join will not be successful, as we’ll need to merge the state, county, and tract columns from va_df together to make it parallel to the GEOID column from va_tract. We can simply add the columns together, much like math or the basic operators in Python, and assign the “sum” to a new column.
To create a new column–or call an existing column in a dataframe–we can use indexing with [] and the column name (string). (There is a different way if you want to access columns using the index number; read more about indexing and selecting data in the pandas documentation.)
# Combine state, county, and tract columns together to create a new string and assign to new column
va_df["GEOID"] = va_df["state"] + va_df["county"] + va_df["tract"]
Printing out the first rew rows of the dataframe, we can see that the new column GEOID has been created with the values from the three columns combined.
# Print head of dataframe
va_df.head(2)
| NAME | C17002_001E | C17002_002E | C17002_003E | B01003_001E | state | county | tract | GEOID | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Census Tract 60, Norfolk city, Virginia | 3947.0 | 284.0 | 507.0 | 3947.0 | 51 | 710 | 006000 | 51710006000 |
| 1 | Census Tract 65.02, Norfolk city, Virginia | 3287.0 | 383.0 | 480.0 | 3302.0 | 51 | 710 | 006502 | 51710006502 |
Remove dataframe columns that are no longer needed#
To reduce clutter, we can delete the state, county, and tract columns from va_df since we don’t need them anymore. Remember that when we want to modify a dataframe, we must assign the modified dataframe back to the original variable (or a new one, if preferred). Otherwise, any modifications won’t be saved. An alternative to assigning the dataframe back to the variable is to simply pass inplace = True. For more information, see the pandas help documentation on drop.
# Remove columns
va_df = va_df.drop(columns = ["state", "county", "tract"])
# Show updated dataframe
va_df.head(2)
| NAME | C17002_001E | C17002_002E | C17002_003E | B01003_001E | GEOID | |
|---|---|---|---|---|---|---|
| 0 | Census Tract 60, Norfolk city, Virginia | 3947.0 | 284.0 | 507.0 | 3947.0 | 51710006000 |
| 1 | Census Tract 65.02, Norfolk city, Virginia | 3287.0 | 383.0 | 480.0 | 3302.0 | 51710006502 |
Check column data types#
The key in both dataframe must be of the same data type. Let’s check the data type of the GEOID columns in both dataframes. If they aren’t the same, we will have to change the data type of columns to make them the same.
# Check column data types for census data
print("Column data types for census data:\n{}".format(va_df.dtypes))
# Check column data types for census shapefile
print("\nColumn data types for census shapefile:\n{}".format(va_tract.dtypes))
# Source: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dtypes.html
Column data types for census data:
NAME object
C17002_001E float64
C17002_002E float64
C17002_003E float64
B01003_001E float64
GEOID object
dtype: object
Column data types for census shapefile:
STATEFP object
COUNTYFP object
TRACTCE object
GEOID object
NAME object
NAMELSAD object
MTFCC object
FUNCSTAT object
ALAND int64
AWATER int64
INTPTLAT object
INTPTLON object
geometry geometry
dtype: object
Looks like the GEOID columns are the same!
Merge dataframes#
Now, we are ready to merge the two dataframes together, using the GEOID columns as the primary key. We can use the merge method in GeoPandas called on the va_tract shapefile dataset.
# Join the attributes of the dataframes together
# Source: https://geopandas.org/docs/user_guide/mergingdata.html
va_merge = va_tract.merge(va_df, on = "GEOID")
# Show result
print(va_merge.head(2))
print('Shape: ', va_merge.shape)
STATEFP COUNTYFP TRACTCE GEOID NAME_x NAMELSAD MTFCC \
0 51 700 032132 51700032132 321.32 Census Tract 321.32 G5020
1 51 700 032226 51700032226 322.26 Census Tract 322.26 G5020
FUNCSTAT ALAND AWATER INTPTLAT INTPTLON \
0 S 2552457 0 +37.1475176 -076.5212499
1 S 3478916 165945 +37.1625163 -076.5527816
geometry \
0 POLYGON ((897174.191 4119897.084, 897174.811 4...
1 POLYGON ((893470.562 4123469.385, 893542.722 4...
NAME_y C17002_001E C17002_002E \
0 Census Tract 321.32, Newport News city, Virginia 5025.0 161.0
1 Census Tract 322.26, Newport News city, Virginia 4167.0 736.0
C17002_003E B01003_001E
0 342.0 5079.0
1 559.0 4167.0
Shape: (1907, 18)
Success! We still have 1907 rows, which means that all rows (or most of them) were successfully matched! Notice how the census data has been added on after the shapefile data in the dataframe.
Some additional notes about joining dataframes:
the columns for the key do not need to have the same name.
for this join, we had a one-to-one relationship, meaning one attribute in one dataframe matched to one (and only one) attribute in the other dataframe. Joins with a many-to-one, one-to-many, or many-to-many relationship are also possible, but in some cases, they require some special considerations. See this Esri ArcGIS help documentation on joins and relates for more information.
Subset dataframe#
Now that we merged the dataframes together, we can further clean up the dataframe and remove columns that are not needed. Instead of using the drop method, we can simply select the columns we want to keep and create a new dataframe with those selected columns.
# Create new dataframe from select columns
va_poverty_tract = va_merge[["STATEFP", "COUNTYFP", "TRACTCE", "GEOID", "geometry", "C17002_001E", "C17002_002E", "C17002_003E", "B01003_001E"]]
# Show dataframe
print(va_poverty_tract.head(2))
print('Shape: ', va_poverty_tract.shape)
STATEFP COUNTYFP TRACTCE GEOID \
0 51 700 032132 51700032132
1 51 700 032226 51700032226
geometry C17002_001E \
0 POLYGON ((897174.191 4119897.084, 897174.811 4... 5025.0
1 POLYGON ((893470.562 4123469.385, 893542.722 4... 4167.0
C17002_002E C17002_003E B01003_001E
0 161.0 342.0 5079.0
1 736.0 559.0 4167.0
Shape: (1907, 9)
Notice how the number of columns dropped from 13 to 9.
Dissolve geometries and get summarized statistics to get poverty statistics at the county level#
Next, we will group all the census tracts within the same county (COUNTYFP) and aggregate the poverty and population values for those tracts within the same county. We can use the dissolve function in GeoPandas, which is the spatial version of groupby in pandas. We use dissolve instead of groupby because the former also groups and merges all the geometries (in this case, census tracts) within a given group (in this case, counties).
# Dissolve and group the census tracts within each county and aggregate all the values together
# Source: https://geopandas.org/docs/user_guide/aggregation_with_dissolve.html
va_poverty_county = va_poverty_tract.dissolve(by = 'COUNTYFP', aggfunc = 'sum')
# Show dataframe
print(va_poverty_county.head(2))
print('Shape: ', va_poverty_county.shape)
geometry \
COUNTYFP
001 POLYGON ((971814.409 4160130.005, 971664.507 4...
003 POLYGON ((722871.236 4189239.708, 722813.526 4...
STATEFP \
COUNTYFP
001 515151515151515151515151
003 51515151515151515151515151515151515151515151
TRACTCE \
COUNTYFP
001 0902009802009801000904000903000908009902000906...
003 0113030112010112020102020102010104010104020113...
GEOID C17002_001E \
COUNTYFP
001 5100109020051001980200510019801005100109040051... 32345.0
003 5100301130351003011201510030112025100301020251... 97587.0
C17002_002E C17002_003E B01003_001E
COUNTYFP
001 2423.0 3993.0 32840.0
003 5276.0 4305.0 105105.0
Shape: (133, 8)
Notice that we got the number of rows down from 1907 to 133.
Perform column math to get poverty rates#
We can estimate the poverty rate by dividing the sum of C17002_002E (ratio of income to poverty in the past 12 months, < 0.50) and C17002_003E (ratio of income to poverty in the past 12 months, 0.50 - 0.99) by B01003_001E (total population).
Side note: Notice that C17002_001E (ratio of income to poverty in the past 12 months, total), which theoretically should count everyone, does not exactly match up with B01003_001E (total population). We’ll disregard this for now since the difference is not too significant.
# Get poverty rate and store values in new column
va_poverty_county["Poverty_Rate"] = (va_poverty_county["C17002_002E"] + va_poverty_county["C17002_003E"]) / va_poverty_county["B01003_001E"] * 100
# Show dataframe
va_poverty_county.head(2)
| geometry | STATEFP | TRACTCE | GEOID | C17002_001E | C17002_002E | C17002_003E | B01003_001E | Poverty_Rate | |
|---|---|---|---|---|---|---|---|---|---|
| COUNTYFP | |||||||||
| 001 | POLYGON ((971814.409 4160130.005, 971664.507 4... | 515151515151515151515151 | 0902009802009801000904000903000908009902000906... | 5100109020051001980200510019801005100109040051... | 32345.0 | 2423.0 | 3993.0 | 32840.0 | 19.537150 |
| 003 | POLYGON ((722871.236 4189239.708, 722813.526 4... | 51515151515151515151515151515151515151515151 | 0113030112010112020102020102010104010104020113... | 5100301130351003011201510030112025100301020251... | 97587.0 | 5276.0 | 4305.0 | 105105.0 | 9.115646 |
Plotting Results#
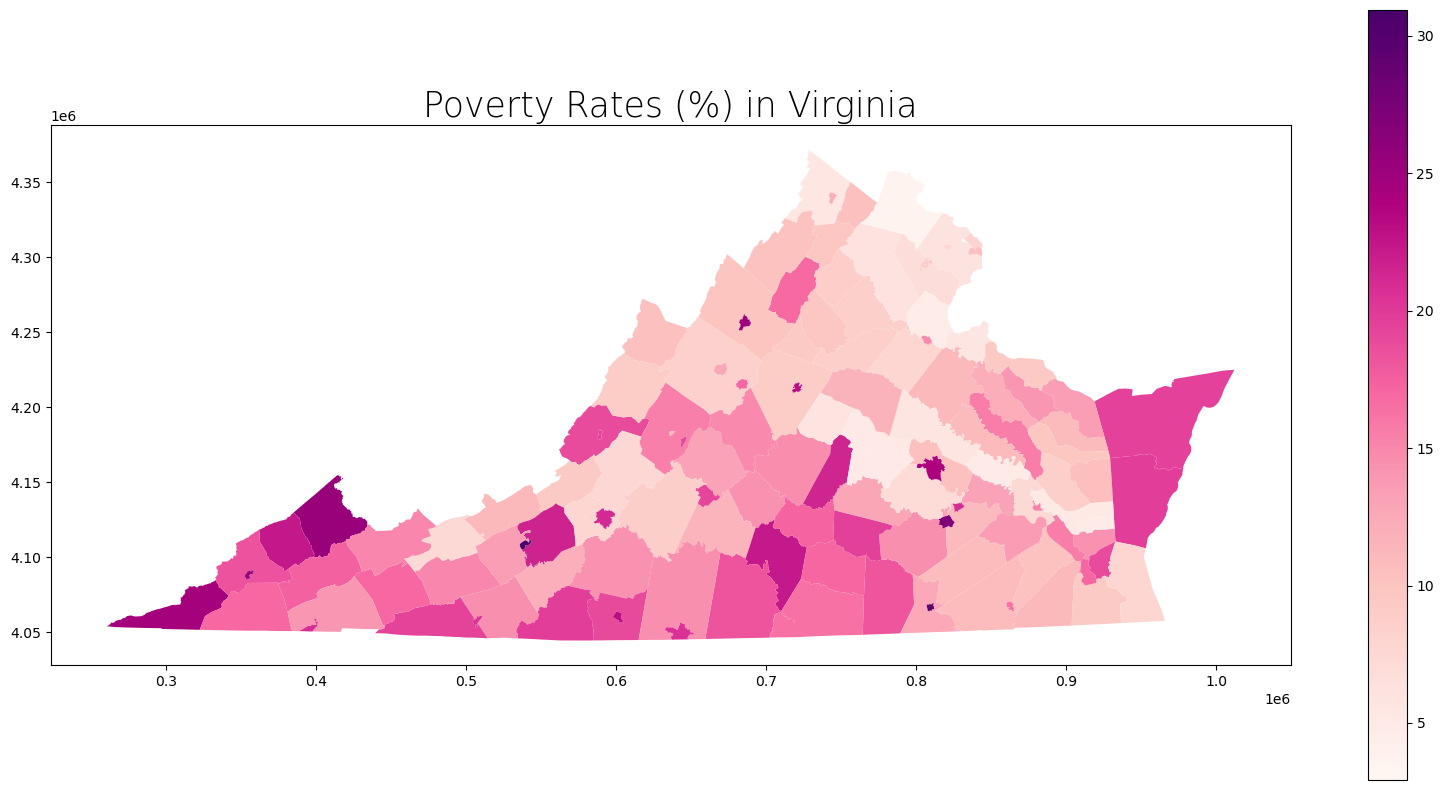
Finally, since we have the spatial component connected to our census data, we can plot the results!
# Create subplots
fig, ax = plt.subplots(1, 1, figsize = (20, 10))
# Plot data
# Source: https://geopandas.readthedocs.io/en/latest/docs/user_guide/mapping.html
va_poverty_county.plot(column = "Poverty_Rate",
ax = ax,
cmap = "RdPu",
legend = True)
# Stylize plots
plt.style.use('bmh')
# Set title
ax.set_title('Poverty Rates (%) in Virginia', fontdict = {'fontsize': '25', 'fontweight' : '3'})
Text(0.5, 1.0, 'Poverty Rates (%) in Virginia')